Auto-Surprise: Automates Algorithm and Hyperparameter Tuning
Algorithm selection and hyperparameters tuning are tedious yet important steps in the machine learning pipeline. The performance of the final model highly dependent on the algorithm and choice of hyperparameters. Manually random search and GridSearch waste time when investigating unpromising areas of the search space. Therefore, an automated method becomes necessary in these optimization steps. Auto-Surprise exactly meets these expectations. It is easy to use even for tyros who are not familiar with potential algorithm and hyperparameter tuning.
Auto-Surprise is a python library that automates algorithm selection and hyperparameter optimization in a highly parallelized manner. It is built on popular library Surprise for recommender algorithms and Hyperopt for hyperparameter tuning.
Quick Start:
It requires Python >= 3.6 and a Linux based OS. To install Auto-Surprise library:
pip install auto-surprise
Then you are good to use it.
Usage:
1. Initializing Auto-Surprise Engine
Engine is the main class for Auto Surprise, which need to be initialized before use:
engine = Engine(verbose=True, algorithms=[‘svd’, ‘svdpp’, ‘knn_basic’, ‘knn_baseline’])
- algorithms must be in the form of an array of strings.
- Available algorithm choices are: ‘svd’, ‘svdpp’, ‘nmf’, ‘knn_basic’, ‘knn_baseline’, ‘knn_with_means’, ‘knn_with_z_score’, ‘co_clustering’, ‘slope_one’, ‘baseline_only’
2. Starting the Optimization process
Use train method of Engine to get the best algorithm, hyperparameters, best score, and tasks completed:
best_algo, best_params, best_score, tasks = engine.train(
data=data,
target_metric='test_rmse',
cpu_time_limit=60*60*2,
max_evals=100,
hpo_algo=hyperopt.tpe.suggest
)
- data: An instance of surprise.dataset.DatasetAutoFolds.
- target_metric: The metric we seek to minimize. Available options are test_rmse and test_mae.
- cpu_time_limit: The time limit we want to train.
- max_evals: The maximum number of evaluations each algorithm gets for hyperparameter optimization.
- hpo_algo: Auto-Surprise uses Hyperopt for hyperparameter tuning.
3. Building the best Model
The best model is built on the best algorithm and the best parameters:
best_model = engine.build_model(best_algo, best_params)
You can pickle this to save it for future use.
4. Reproducing experiments
To make the result reproducible, you can set the seed and random state when initializing Engine:
random.seed(123)
numpy.random.seed(123)
engine = Engine(verbose=True, random_state=numpy.random.RandomState(123))
5. Evaluation
There are tests against three datasets to evaluate Auto-Surprise:
- Movielens 100k
- Jester Dataset 2 (100k Random sample)
- Book Crossing (100k random sample)
All the following results are based on the default configuration. Auto-Surprise running time is limited to 2 hours:
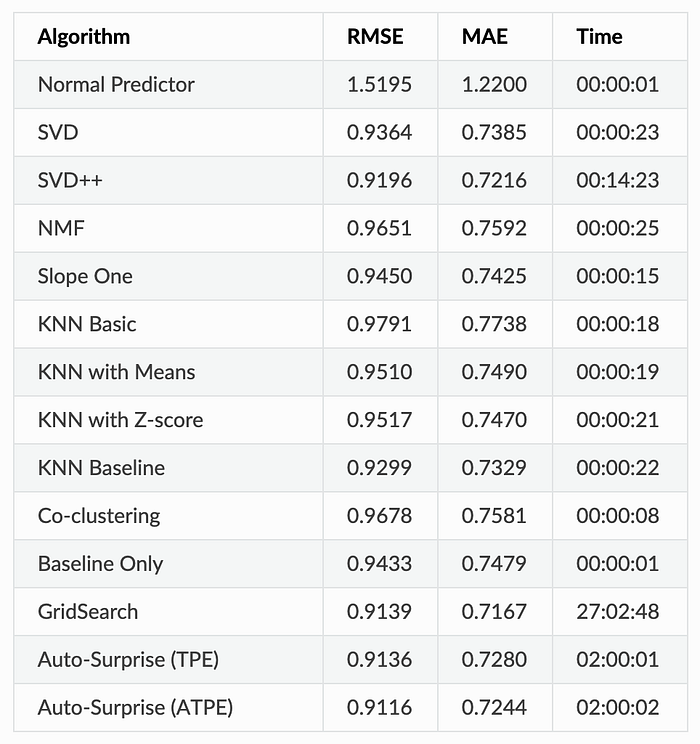
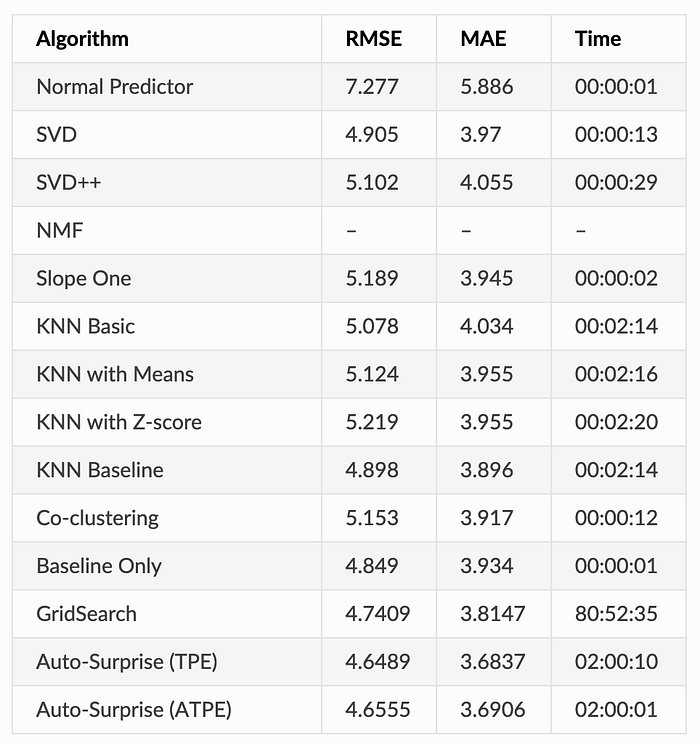
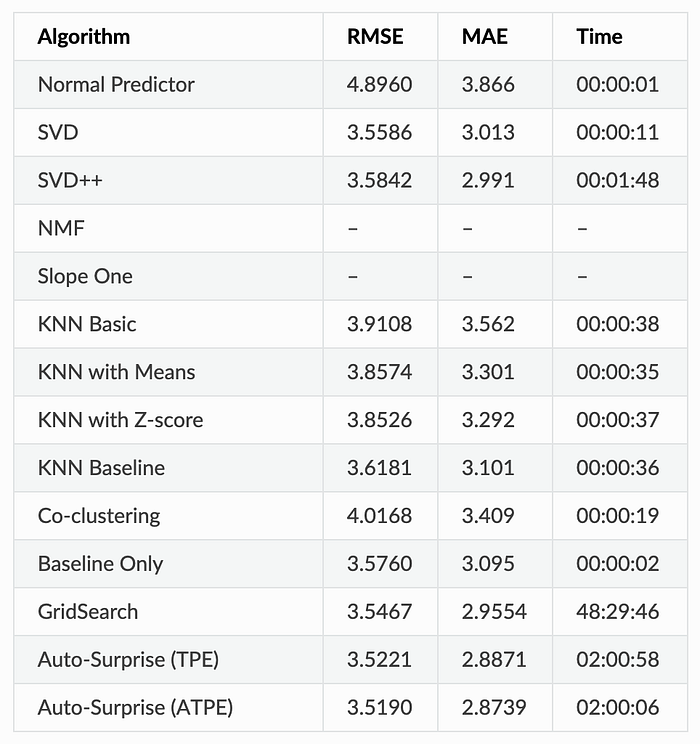
From these results, we can tell that an improvement of anywhere from 0.8–4.0 % in RMSE. And the time taken to evaluate for Auto-Surprise is greatly reduced compared to GridSearch.
Movie streaming example:
Here is a simple example of Auto-Surprise in the context of the movie streaming scenario. The target is to build a recommendation service for a scenario of a movie streaming service.
Apache Kafka was used to read streaming messages as training data from the cluster. The format of data was of the form (user_id, movie_name, rating).
Install the libraries needed:

After data was loaded and preprocessed:
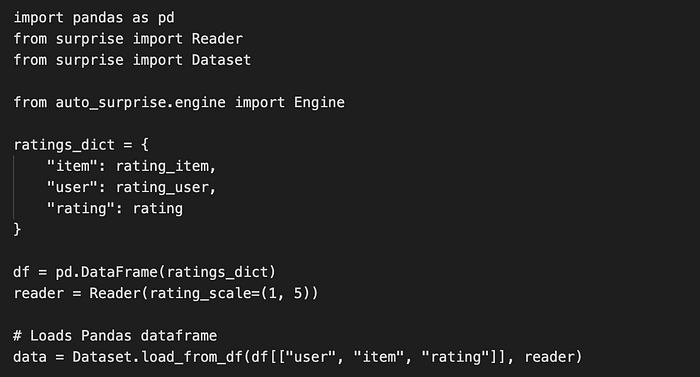
Instead of choosing algorithm and tuning hyperparameter manually, Auto-Surprise was used to automatic algorithm selection and hyperparameters optimization:
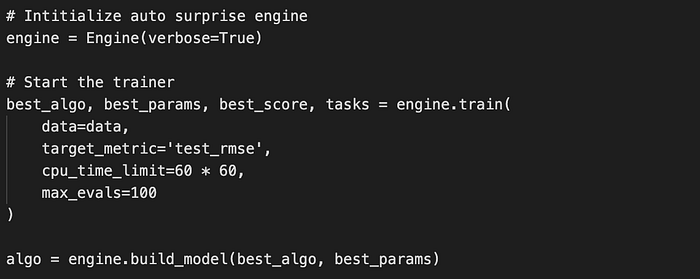
Train the model and predict the rating result:
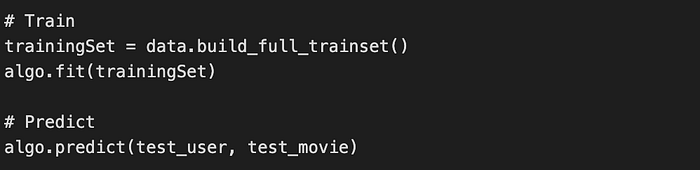
Given the functionality of predicting rating, you can find the highest recommended movie for the user and deploy the model the way you want.
Strength:
1. It is easy to use even for tyros who are not familiar with potential algorithm and hyperparameter tuning.
2. It covers a wide range of algorithms for recommender systems.
3. It saves time compared to GridSearch significantly.
Limitations:
1. It is still time-consuming resulted from its heavy computational overhead.
2. It can be only applied to Surprise library.
3. Currently, only Linux systems are supported.
Reference:
1. “Welcome to Auto-Surprise’s Documentation!¶.” Auto, auto-surprise.readthedocs.io/en/stable/index.html.
2. BeelGroup. “BeelGroup/Auto-Surprise.” GitHub, github.com/BeelGroup/Auto-Surprise/tree/cfbf779cb2d419278b399342b2ecb342106e0247.
